15/06/2026 03:12น.
Golang The Series EP.151: What is RAG?: ทำไม AI ต้องมีฐานข้อมูลส่วนตัว
#Golang
#Go Language
#Go
#RAG
#Retrieval Augmented Generation
#LLM
#AI Chatbot
ยินดีต้อนรับเข้าสู่ EP.151 ครับ! หลังจากที่เราทำ Workshop สร้าง AI Chatbot Server ด้วย Gin Framework ไปในตอนที่แล้ว หลายคนน่าจะเริ่มเจอปัญหาคลาสสิกคือ "AI ไม่รู้จักข้อมูลภายในองค์กรของเรา"
เวลาถามเรื่องทั่วไป AI ตอบได้เป๊ะมาก แต่พอถามเรื่องเฉพาะเจาะจง เช่น ยอดขายเดือนที่แล้ว สเปกสินค้าใหม่ หรือคู่มือพนักงาน AI จะเริ่ม "เดาคำตอบมั่วๆ" (หรือที่เรียกว่า Hallucination) ทันที
วันนี้เราจะมาเจาะลึกแนวคิด RAG (Retrieval-Augmented Generation) หรือการสร้าง "คลังความรู้ส่วนตัว" ให้ AI ซึ่งเป็นหัวใจสำคัญของการพัฒนา AI ในระดับองค์กรครับ
ปัญหาของ LLM
โมเดลอย่าง GPT-4o หรือ Llama 3 ถูกฝึก (Train) มาจากข้อมูลสาธารณะมหาศาล ทำให้เก่งเรื่องความรู้รอบตัว แต่มีข้อจำกัดหลัก 3 อย่างที่แก้ไม่ได้ด้วยการเทรนปกติ:
Knowledge Cutoff: รู้เฉพาะข้อมูลย้อนหลังถึงวันที่เทรนเสร็จ ข้อมูลเรียลไทม์หรือเหตุการณ์วันนี้มันจะไม่รู้เลย
Private Data Blindness: เข้าไม่ถึงเอกสารลับ โค้ดใน Repo หรือฐานข้อมูลลูกค้าที่อยู่หลัง Firewall ของเรา
Hallucination: เมื่อไม่มีข้อมูล แต่มันถูกออกแบบมาให้ต้องตอบ มันจึงสร้างเรื่องโกหกที่ดูน่าเชื่อถือขึ้นมาแทน
RAG คืออะไร? (Retrieval-Augmented Generation)
ถ้า LLM คือ "นักเรียนที่เข้าสอบโดยใช้แค่ความจำ" (ซึ่งจำข้อมูลภายในองค์กรเราไม่ได้) RAG ก็คือการ "อนุญาตให้นักเรียนเปิดคู่มือเข้าไปสอบได้ (Open-book Exam)" นั่นเองครับ
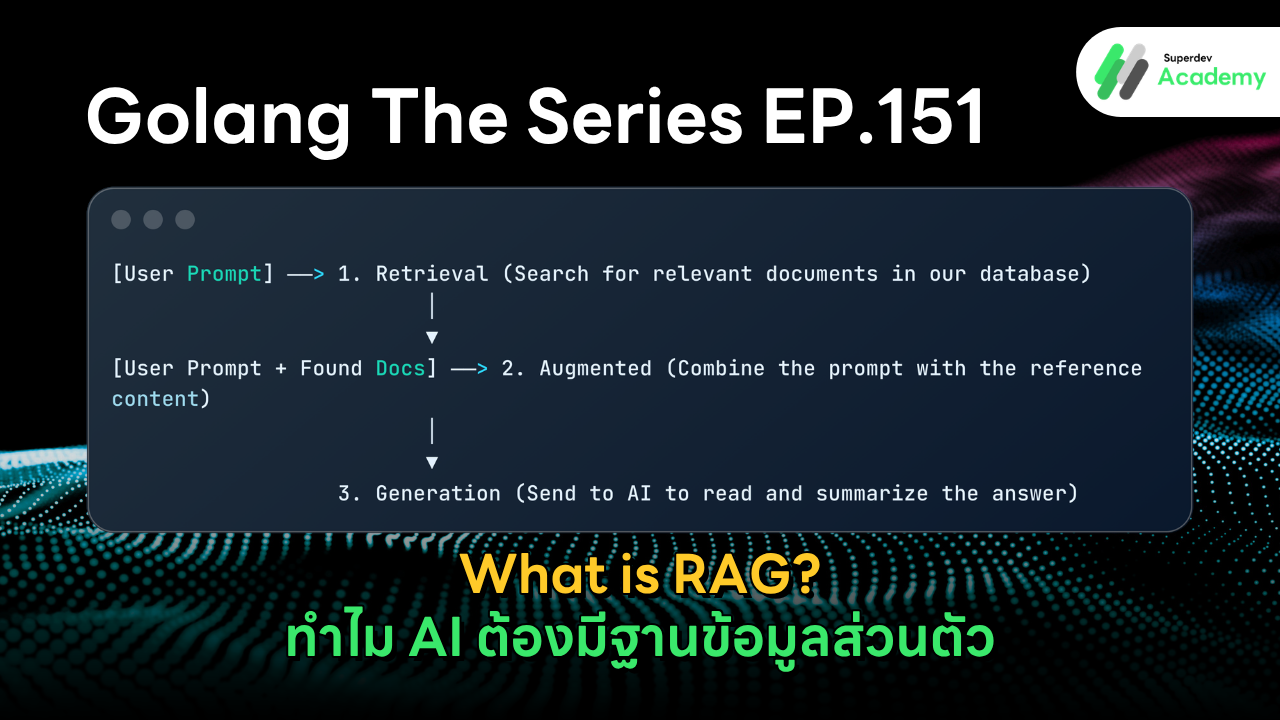
แทนที่จะส่งแค่คำถาม (Prompt) ของ User ไปให้ AI ตรงๆ ระบบ Backend ของเราจะทำงาน 3 จังหวะ ดังนี้:
Plaintext
[User Prompt] ──> 1. Retrieval (ค้นหาเอกสารที่เกี่ยวข้องในฐานข้อมูลเรา)
│
▼
[User Prompt + เอกสารที่เจอ] ──> 2. Augmented (มัดรวมคำถาม + เนื้อหาอ้างอิง)
│
▼
3. Generation (ส่งให้ AI อ่านและสรุปคำตอบจากข้อมูลนั้น)
Retrieval (ค้นคืน): เมื่อมีคำถามเข้ามา Backend จะวิ่งไปค้นในฐานข้อมูลส่วนตัวของเราก่อนว่ามีเอกสารหน้าไหนที่เกี่ยวข้องกับเรื่องนี้บ้าง
Augmented (เสริมบริบท): นำเนื้อหาที่ค้นเจอมาแปะไปกับคำถามเดิมของ User
Generation (สร้างคำตอบ): หน้าที่ของ AI จะเปลี่ยนจากการคิดเอาเอง เป็นการอ่านและสรุปจากเอกสารที่เราแนบไปให้ ทำให้คำตอบแม่นยำ ตรงข้อเท็จจริง และอ้างอิงได้จริง
ทำไม Gopher ถึงต้องเป็นคนทำ RAG?
การทำ RAG แทบไม่ต้องยุ่งกับการเทรนโมเดล (Fine-tuning) เลยครับ งาน 90% คือการจัดการ Data Pipeline ซึ่งเป็นจุดแข็งของภาษา Go อยู่แล้ว:
Concurrency at Scale: การตัดแบ่งเอกสารหมื่นหน้า (Chunking) และแปลงเป็นตัวเลข (Embedding) พร้อมกันหลายๆ Thread สามารถใช้ Goroutines ทำงานแบบ Parallel ได้เร็วกว่าภาษาอื่นอย่างเห็นได้ชัด
Stream Processing: ภาษา Go ถูกออกแบบมาเพื่อจัดการข้อมูลที่ไหลมาเป็น Stream ซึ่งเหมาะมากกับ AI ที่ต้องตอบโต้แบบเรียลไทม์ (Streaming Response)
Reliability: ในระบบ RAG ขนาดใหญ่ที่ต้องเชื่อมต่อกับฐานข้อมูลหลายตัว โครงสร้างแบบ Strongly Typed ของ Go จะช่วยดักจับ Error ได้ตั้งแต่ตอนเขียนโค้ด ทำให้ระบบเสถียรและพังยาก
🎯 Daily Mission: ท้าให้ลองออกแบบ Prompt
สมมติคุณมี "คู่มือลาพักร้อน" อยู่ 1 หน้า และอยากให้ AI ตอบคำถามโดยใช้ข้อมูลแค่ในหน้านี้เท่านั้น
การบ้าน: ลองออกแบบ System Prompt ในใจดูครับว่า ถ้าเราต้องเอา "เนื้อหาคู่มือ" + "คำถาม User" ส่งไปให้ OpenAI (ในโค้ดจาก EP.150) เราควรจะสั่ง AI ว่าอย่างไร เพื่อล็อกให้มันตอบเฉพาะข้อมูลที่ให้ไป และห้ามเดาเนื้อหาภายนอก?
❓ FAQ: คำถามที่พบบ่อยเกี่ยวกับ RAG
ทำ RAG กับทำ Fine-tuning ต่างกันอย่างไร?
Fine-tuning คือการเทรนเพื่อปรับพฤติกรรมหรือสไตล์การพูดของ AI เหมือนการส่งคนไปเรียนคอร์สเฉพาะทางเพิ่ม ส่วน RAG คือการให้คู่มืออ้างอิง ข้อมูลใน RAG สามารถอัปเดตใหม่ได้ตลอดเวลาโดยไม่ต้องเสียเงินและเวลาเทรนโมเดลใหม่ครับ
ข้อมูลที่เราส่งให้ AI ผ่าน RAG จะปลอดภัยไหม?
หากเราใช้บริการผ่าน Enterprise API (เช่น OpenAI API ระดับองค์กร) ข้อมูลที่เราส่งไปใน Prompt จะไม่ถูกนำไปใช้เทรนโมเดลต่อ ทำให้ข้อมูลภายในองค์กรยังคงเป็นความลับ
จำเป็นต้องใช้ฐานข้อมูลแบบพิเศษไหม?
จำเป็นครับ ในระบบ RAG เราจะนิยมใช้ Vector Database (เช่น Milvus, Qdrant, PGVector) เพื่อช่วยให้ AI ค้นหาเอกสารจาก "ความหมาย" ของคำได้ แทนที่จะค้นจาก Key-word ตรงๆ แบบฐานข้อมูลทั่วไป
📌 บทสรุป (Conclusion)
การทำ RAG (Retrieval-Augmented Generation) คือทางออกที่ดีและคุ้มค่าที่สุดในการเปลี่ยนให้ AI ระดับโลก กลายมาเป็น "ผู้เชี่ยวชาญที่รู้ลึกรู้จริงเรื่องในองค์กรของคุณ" โดยที่คุณไม่ต้องลงทุนมหาศาลเพื่อเทรนโมเดลเองตั้งแต่ต้น
และการเลือกใช้ ภาษา Go ในการคุมระบบ Data Pipeline ด้านหลัง จะช่วยการันตีได้ว่าระบบ RAG ของคุณจะทำงานได้อย่างรวดเร็ว รองรับปริมาณเอกสารจำนวนมาก และมีความเสถียรในระดับที่ใช้งานบน Production จริงได้อย่างมั่นใจครับ
ในตอนต่อไป (EP.152): การทำ RAG เราไม่สามารถใช้ LIKE '%คำค้น%' แบบ SQL เดิมๆ ได้ เพราะ AI ค้นหาด้วยความหมาย ไม่ใช่แค่ตัวอักษร ตอนหน้าเรามาเจาะลึก "Intro to Embeddings: เปลี่ยนข้อความให้เป็นตัวเลข (Vectors) ด้วย Go" ก้าวแรกสู่ระบบค้นหาอัจฉริยะ ห้ามพลาดครับ!
ฝากกดติดตามพวกเราได้ที่ Superdev Academy ในทุกช่องทางนะครับ!
🔵 Facebook: Superdev Academy Thailand (อัปเดตข่าวสารและบทความใหม่)
🎬 YouTube: Superdev Academy Channel (ติวเข้มแบบวิดีโอ)
📸 Instagram: @superdevacademy (เกร็ดความรู้สั้นๆ และเบื้องหลังการทำงาน)
🎬 TikTok: @superdevacademy (Tips & Tricks ฉบับย่อยง่าย)
🌐 Website: superdevacademy.com (คลังบทความและคอร์สเรียนฉบับเต็ม)